During development of a grid management system, I initially planned to use PostgreSQL for storing grid WKT data (for direct SHP export and map service publishing). Due to incompatibility with backend framework requirements, I switched to MySQL. This necessitated converting MySQL-stored WKT to Shapefiles. The solution: Java scheduled tasks invoking Python scripts to automate conversion. Below are the code implementations.
1. WKT to Shapefile Conversion
Preview: 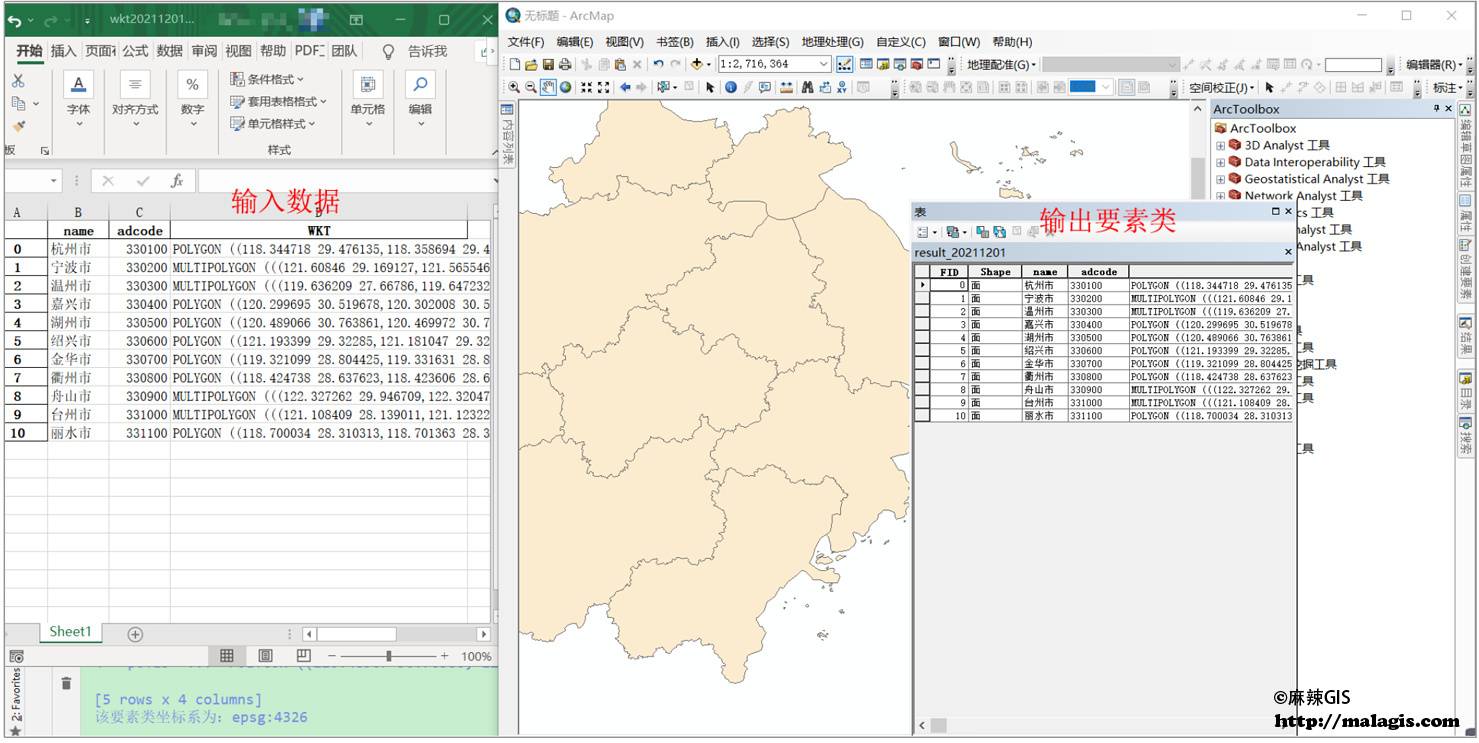
Code:
import osr
import datetime
import pandas as pd
from osgeo import ogr
Input/Output paths
input_excel = r'./data/wkt_data.xlsx'
output_shp = r"./output/shp/grid_{}.shp".format(datetime.datetime.now().strftime('%Y%m%d'))
# Create Shapefile
driver = ogr.GetDriverByName("ESRI Shapefile")
ds = driver.CreateDataSource(output_shp)
srs = osr.SpatialReference()
srs.ImportFromEPSG(4326) # WGS84
layer = ds.CreateLayer("grid_polygons", srs, ogr.wkbPolygon)
# Define fields
fields = [
("name", ogr.OFTString, 20),
("adcode", ogr.OFTString, 100),
("wkt", ogr.OFTString, 254)
]
for name, ftype, width in fields:
field_def = ogr.FieldDefn(name, ftype)
field_def.SetWidth(width)
layer.CreateField(field_def)
# Feature creation function
def create_feature(layer, name, adcode, wkt_str):
feature = ogr.Feature(layer.GetLayerDefn())
feature.SetField("name", name.encode("gbk").decode('ISO-8859-1'))
feature.SetField("adcode", adcode)
feature.SetField("wkt", wkt_str)
geom = ogr.CreateGeometryFromWkt(wkt_str)
feature.SetGeometry(geom)
layer.CreateFeature(feature)
# Process Excel data
df = pd.read_excel(input_excel)
for _, row in df.iterrows():
create_feature(layer, row['name'], row['adcode'], row['WKT'])
ds = None # Save and close2. Shapefile to WKT Export
Input Data: 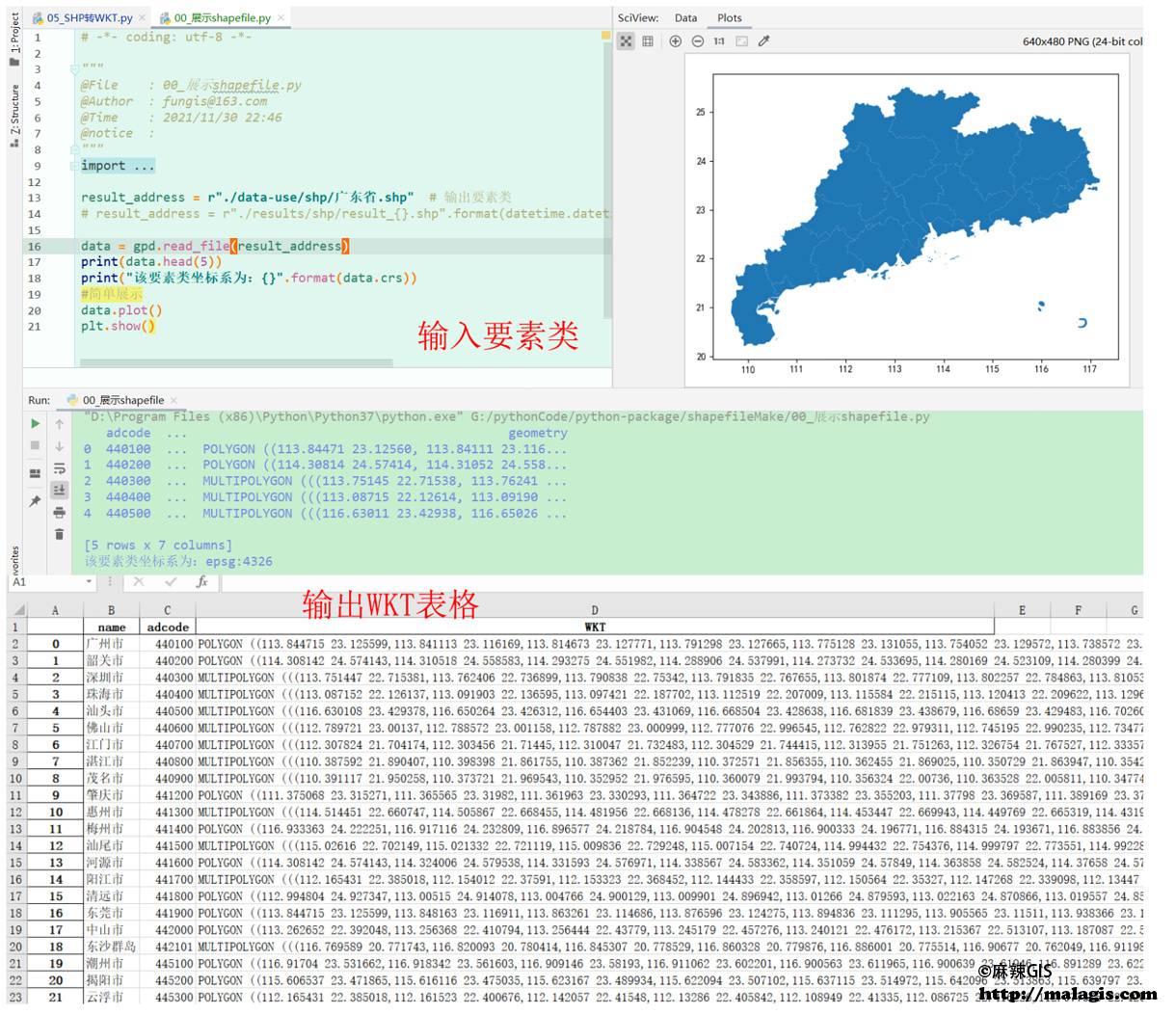
Code:
import pandas as pd
from osgeo import ogr
input_shp = r"./data/Guangdong.shp"
output_excel = r'./output/wkt_export.xlsx'
# Read Shapefile
ds = ogr.Open(input_shp)
layer = ds.GetLayer()
field_names = [layer.GetLayerDefn().GetFieldDefn(i).GetName() for i in range(layer.GetLayerDefn().GetFieldCount())]
# Extract data
records = []
for feature in layer:
record = []
for field in field_names:
record.append(feature.GetField(field))
geom = feature.GetGeometryRef()
record.append(geom.ExportToWkt()) # Append WKT
records.append(record)
# Export to Excel
df = pd.DataFrame(records, columns=field_names + ['WKT'])
df.to_excel(output_excel, index=False)3. Tabular Data to Shapefile
Output Preview: 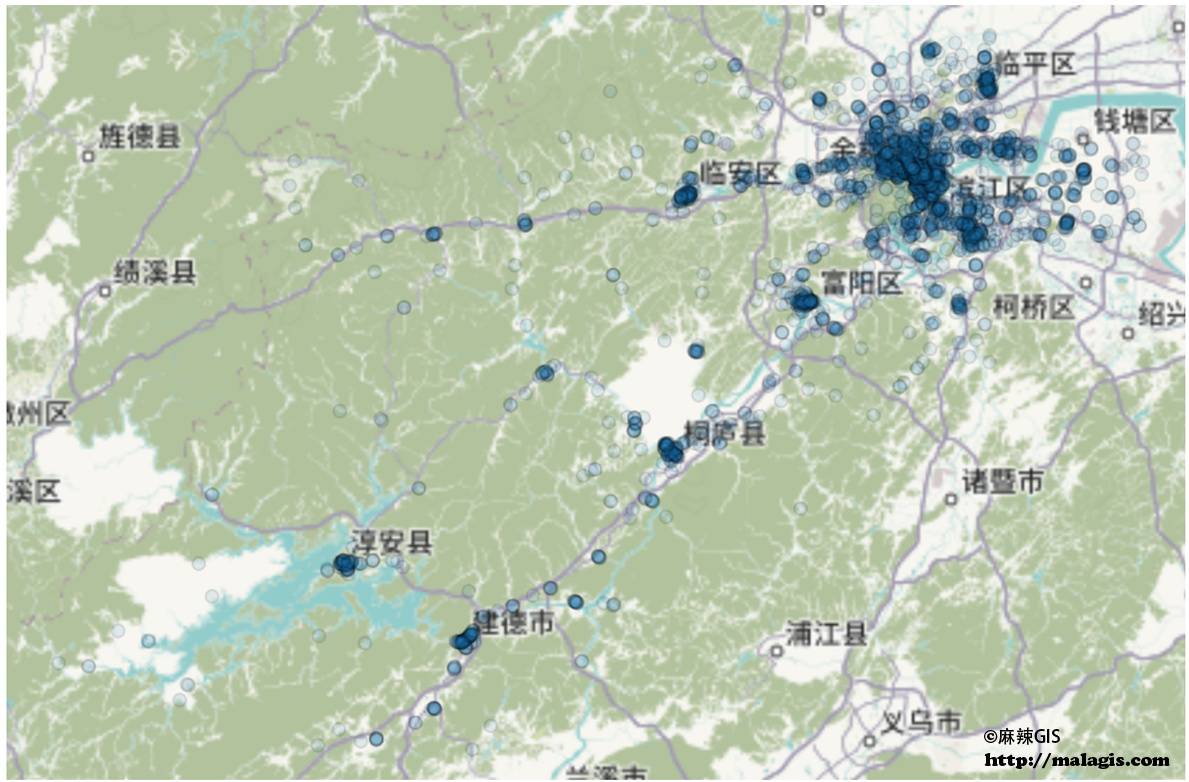
Code:
import shapefile
import pandas as pd
import os
input_csv = r'./data/hangzhou_atm.csv'
output_shp = './output/poi_atm.shp'
# Read CSV
df = pd.read_csv(input_csv)
# Create Shapefile
sf = shapefile.Writer(output_shp, shapeType=shapefile.POINT)
# Define fields
field_specs = {
'business_area': ('C', 100),
'cityname': ('C', 100),
'id': ('N', 10),
'lat': ('F', 15, 10),
'lon': ('F', 15, 10),
'name': ('C', 100),
'pname': ('C', 100)
}
for name, (ftype, *args) in field_specs.items():
sf.field(name, ftype, *args)
# Add records
for _, row in df.iterrows():
sf.point(float(row['lon']), float(row['lat']))
sf.record(*[row[col] for col in field_specs.keys()])
sf.close()
# Add projection (WGS84)
with open(output_shp.replace('.shp', '.prj'), 'w') as prj:
prj.write('GEOGCS["WGS 84",DATUM["WGS_1984",SPHEROID["WGS 84",6378137,298.257223563]],PRIMEM["Greenwich",0],UNIT["degree",0.0174532925199433]]')Conclusion
These scripts enable seamless conversion between common GIS data formats. For environment management, I recommend Miniconda with Chinese mirrors for faster package installation.
Full code and sample data:
https://gitee.com/fungiser/python-shapefile-operate